
Data2Share
How to: een werkproces automatiseren met behulp van een LLM
Iedereen wil wat doen met AI. Wij houden niet zo van die kreet. We draaien het liever om en denken vanuit de core business van je organisatie. Met deze post leggen we uit hoe we verder gaan dan ambities en probleemoplossend worden met behulp van AI.
❌ 𝗪̶𝗶̶𝗷̶ ̶𝘄̶𝗶̶𝗹̶𝗹̶𝗲̶𝗻̶ ̶𝗴̶𝗿̶𝗮̶𝗮̶𝗴̶ ̶𝘄̶𝗮̶𝘁̶ ̶𝗱̶𝗼̶𝗲̶𝗻̶ ̶𝗺̶𝗲̶𝘁̶ ̶𝗔̶𝗜̶
✅ 𝗪𝗶𝗷 𝗵𝗲𝗯𝗯𝗲𝗻 𝗲𝗲𝗻 𝗽𝗿𝗼𝗯𝗹𝗲𝗲𝗺 𝗲𝗻 𝗸𝘂𝗻𝗻𝗲𝗻 𝗱𝗮𝘁 𝗼𝗽𝗹𝗼𝘀𝘀𝗲𝗻 𝗺𝗲𝘁 𝗔𝗜
Aanleiding
In een recente post hebben we aandacht besteed aan een analyse die we hebben gedaan op data opdrachten. Hierin stelden we de ambitie om data opdrachten inzichtelijk te maken met behulp van data. Lees de volledige analyse hier.
Dat vonden wij zelf een heel mooi streven, maar het had ook een nadeel. De inzichten waren voor ons zo relevant, dat het ook leuker en interessanter werd om op steeds meer variabelen te meten.
- Wie zijn de opdrachtgevers, waar zitten ze en waar vragen ze naar?
- Hoeveel kan je vragen per functie en ervaringsniveau?
- Hoe lang duren opdrachten en hoeveel zou je kunnen verdienen aan zo’n klus?
Die crave naar kennis had ook een nadeel. Al gauw waren er per opdracht 22 velden waar we data over verzamelden. Helaas zijn opdrachtomschrijvingen niet per sé heel gestructureerd ingericht waardoor je aandachtig de hele tekst moet lezen om de juiste informatie eruit op te halen. Per opdracht was je al gauw 5 minuten bezig. Met gemiddeld 5 opdrachten per dag zijn dat 5*5*5=125 minuten per week. Ofwel: ruim 2 uur aan data registratie en verrijking!
Een probleem was geboren. Het kost ons (te) veel tijd om die data te blijven verzamelen. Bovendien zijn we liever lui dan moe. Aanleiding om eens te experimenteren met manieren om dit sneller te doen!
Oplossing
Opdrachtomschrijvingen zijn vrij geschreven teksten. Er zitten wel algemene structuren in, maar iedereen doet het net even anders. Zo’n tekst is prima voor menselijke interpretatie, maar lastig voor vaste automatiseringsregels.
Daarom hebben we een oplossing ontwikkeld waarbij een Large Language Model (LLM) het leeswerk van ons overneemt. De uitgangspunten: minimaal handwerk, bruikbaar voor iedereen, mogelijkheid om AI te corrigeren, en gestandaardiseerde output.
Dit levert de volgende stappen op:
- Plak de volledige opdrachtomschrijving in een app en druk op een knop om de analyse te starten.
- AI analyseert de tekst en vult op basis van onze zorgvuldig opgestelde aanwijzingen automatisch de gewenste datavelden in.
- We vertrouwen AI niet 100%. Daarom bouwen we een extra stap in waarin wij de output controleren en waar nodig kunnen bijsturen.
- Na goedkeuring drukken we op een knop om de data automatisch op te slaan in een database.
- Nu staat de data klaar voor verdere analyse en rapportage.

Uitwerking
Nu we weten wat de oplossing precies voor ons moet doen, kunnen we aan de slag met het realiseren ervan. Hiervoor zullen we 3 grote hordes moeten nemen.
1. LLM kiezen en deployen
We onderzochten welk model de juiste balans bood tussen kwaliteit, snelheid en kosten. Omdat wij veelal gebruik maken van de Microsoft Stack hebben we gekozen voor de AI Foundry | Azure OpenAI app. Hierin heb je keuze uit vele OpenAI modellen om te gebruiken voor je pipeline. Je betaalt met tokens die corresponderen met een hoeveelheid karakters die je als input én output van het model vraagt. Output kost iets meer dan input en voor de nieuwste, meest geavanceerde modellen betaal je wat weer meer dan voor de oudere modellen (die veelal ook prima voldoen).
Rekenvoorbeeld:
- Wij kiezen LLM: Azure OpenAI – GPT-4.1 (of GPT-4o)
- 1 woord ≈ 1,3 tokens
- We hebben een opdrachttekst van 2000 woorden input ≈ 2600 tokens
- We ontvangen aan data terug 100 woorden output ≈ 130 tokens
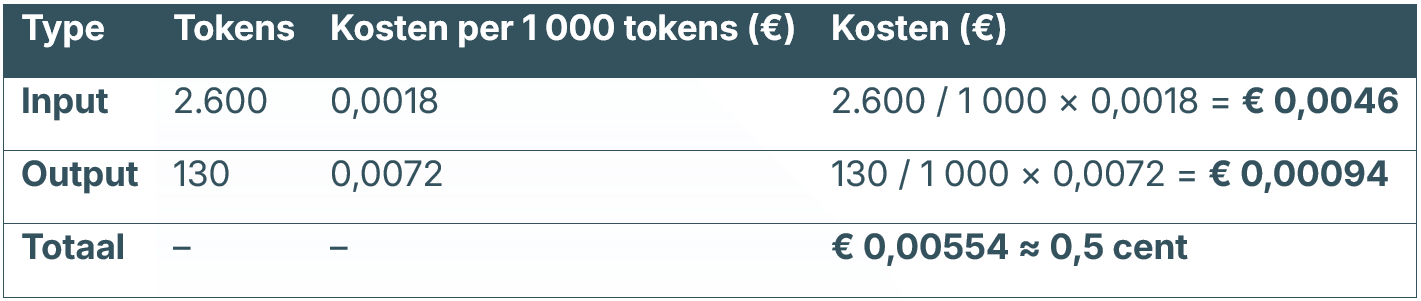
Een halve cent per tekst dus. Bij 25 opdrachten per week betekent dit dus 12,5 cent investeren in ruil voor 2 uur minder handwerk. Klinkt als een prima deal!
2. Testen en tunen in de azure sandbox
Met een model op zak kunnen we aan de slag gaan. In Azure is een sandbox omgeving waarin je kan spelen met het model om verschillende vormen van input en output vorm te geven. Je speelt met een aantal variabelen:
- User message: het bericht dat je als input meegeeft; in ons geval de opdrachtomschrijving.
- System message: hiermee kan je het model denkwijzen, regels, normalisatie, categorieën, etc. meegeven. Hiermee kan je de output sturen naar een voor gewenste structuur.
- Parameters: je kan nog spelen met zaken als de ‘creativiteit’ van het model, maximaal aantal woorden in de output of het aantal antwoorden dat je wil ontvangen.
Wij hebben het model zo getuned dat het heel gestructureerd werkt. Creativiteit is leuk voor marketing doeleinden, maar juist niet als je gestructureerde data voor rapportage doeleinden wil genereren. We geven het model regels mee om de gewenste output te geven en bepalen ook waar die output aan moet voldoen.
Bijvoorbeeld: we vragen om beoordeling op de ervaringsniveaus junior, medior en senior. We geven het model mee dat een senior minimaal 7 jaar ervaring heeft óf dat dit specifiek benoemd is in de tekst. Met deze kennis op zak snapt het model ook echt wat wij bedoelen met senior. We spreken dezelfde taal en onze datakwaliteit is beter!
3. App inrichten voor de gebruikerservaring en datastromen
De AI oplossing is vrij technisch, maar het gebruik ervan moet zo simpel mogelijk zijn. Daarom maken we een app om chat-matig onze gewenste data te genereren. De app is super simpel. Er is een chatbox waarin je je opdrachtomschrijving kan plakken en er zijn 4 knoppen om de data te analyseren, verwijderen, bewerken en bewaren. Het bewerken zien wij als essentiële tussenstap omdat je hiermee het model als mens nog kan controleren en bijsturen waar mogelijk. Ben je tevreden, dan stuur je het met een simpele druk op de knop naar de database en is de klus geklaard.
Conclusie
Voor ons is de oplossing geslaagd. Onze ambitie om inzichten over data opdrachten te leveren is ineens weer veel makkelijker haalbaar. De 2 uur per week zijn verschrompeld tot enkele minuten werk om de teksten in het appje te plakken. Bovendien zijn de kosten voor het LLM op deze schaal te verwaarlozen.
Deze blog is bedoeld om je te inspireren over de mogelijkheden van data en AI in jouw werk. De oplossing is een leuke toepassing voor ons werkproces, maar is natuurlijk ook voor vele andere processen inzetbaar. Ben je benieuwd of dit voor jou ook zou kunnen werken? Neem dan gerust contact met ons op.
.svg)
.svg)
